My site was hacked. Sort of.
A story of when abandoned tech gets assimilated for undesirable purposes. AKA when I inadvertently created a massive open spam proxy. (Although in fairness I can also now say that I have created a site that was creating literally thousands of hits per minute… which is pretty huge.)
Let’s start with some excuses
(Warning: large amount of, shall we say, “scene-setting“.)
I don’t claim to be a web developer. Or certainly I don’t claim to be a very good one. Despite what some of my friends and family may think, it’s not what I do for a job. I know a little bit about a little bit but I am miles behind what some of the bigshots can do with the web nowadays.
But - the web is what got me really interested in computers in the first place. Sure, there was the BBC Micro and the Amstrad and copying lines of code from a manual to make pong and such like from my really early days - but it was the internet that really had the impact. The Internet has literally become A Thing during my lifetime (the really early days obviously pre-date me) but my earliest memories of the consumer internet was Compuserve, AOL, IRC, ICQ, BBS and so on - and for your average wannabe web developer, Geocities, XOOM and Frontpage were the buzzwords of the time.
(I still chuckle when I see the _vti_bin directories in ‘modern’ SharePoint environments.)
Bear in mind this was at a time when server side web programming was mostly limited to PHP, ASP or CGI. Perl had never really cut over and ColdFusion was still a bit of an unknown quantity. Say what you like about it as a technology (and me as a result) but PHP is what grabbed my attention and got me excited about what you could do with a computer. In the mid-90s, making a browser screen change based on some URL params was a huge deal; I remember I asked a forum once that I had some text and I only wanted a part of it and some godlike figure responded to me with strstr(). These are the things that made me go further in to the rabbit hole. I found MySQL and before you knew it I was writing database driven websites and after a while I had become that guy answering the n00b questions in the forums. I branched from the web to compiled to near bare-metal programming and ultimately landing near the topic of geospatial statistics and working on decomposing satellite imagery for optimising land cover classification techniques.
Fast forward, um… quite a lot of years and I know a fair bit more now than I did back then and I still get a huge kick out of it. I kept up with the web for a while but as my needs and interests changed, so did the web, and my career cut a different path. As I learnt more about data and software engineering and the business of being in technology as a job, so the web and the technology evolved. As I became comfortable with allowing framework technologies to do awkward things like memory management for me, the internet became the monster we know and love and hate today. But not only did the number and scope of great things you can do on the web evolve rapidly… so did the range of threats and dangers, at a far greater pace.
not so 1337 (but value =…?)
The “it won’t happen to me” syndrome - aka Optimism Bias - is an especially interesting and relevant concern nowadays. The smokers / drinkers / skydivers / motorcyclists / professional bell-ringers and all manner of other activities - dangerous or otherwise - in other words, all of us - mostly live in denial - or full acceptance - of the risks of our pursuits. And this has never been more true in the age of technology. The ‘Hafnium’ and ‘SolarWinds’ hacks from recent times are testament to the sorts of shenanigans motivated ‘actors’ can get up to - which leaves the little guys like me in a position of false safety - “they’ll never find my little website and exploit it.”
Where I live, number (registration / license) plates on vehicles are all numeric. Numbers available range from (literally) 1 to around 90000 (I forget exactly how far it has gone) and there is a thriving market for vanity plates. There are a few simple rules - the lower the number, the more it’s worth. (Getting a 1 digit plate is unheard of. 2 digit plates will be £30k+). 3 and 4 digit plates are the go to, but even 5 digit plates have some value. And within that there are further variations - where patterns and other factors exist, the value goes up. People like the numbers that are, for instance their birthday. 007 sold a few years ago for £250,000.
(But this was mostly due to two rich people getting in to a “who has the bigger appendage” war.)
As a data geek - this fascinated me, and I set out to see if there was a way to work out the values of these number plates. When I realised that what I had been doing at university some, ahem, 20+ years ago, was actually what we nowadays call machine learning, I set forth. I cobbled together some stuff, and in the end I had what seemed to represent a pretty solid model of valuing number plates. Whether it was really any good is an entirely different matter but nevertheless I had it, in a raw form. Not only did it give you a current market value but it would do some basic trend stuff and I was able to produce an index of values over time.
Interesting!
“Other people need to see this!” I mused.
So I did what any other self-respecting geek with nothing better to do would do; over the course of a few late nights, a bottle of wine or two, I threw together a basic website, and https://digits.gg was born.
It served one purpose - enter a registration number and it would tell you (with a few added bits’n’bobs) a value for it. This bit worked perfectly well.
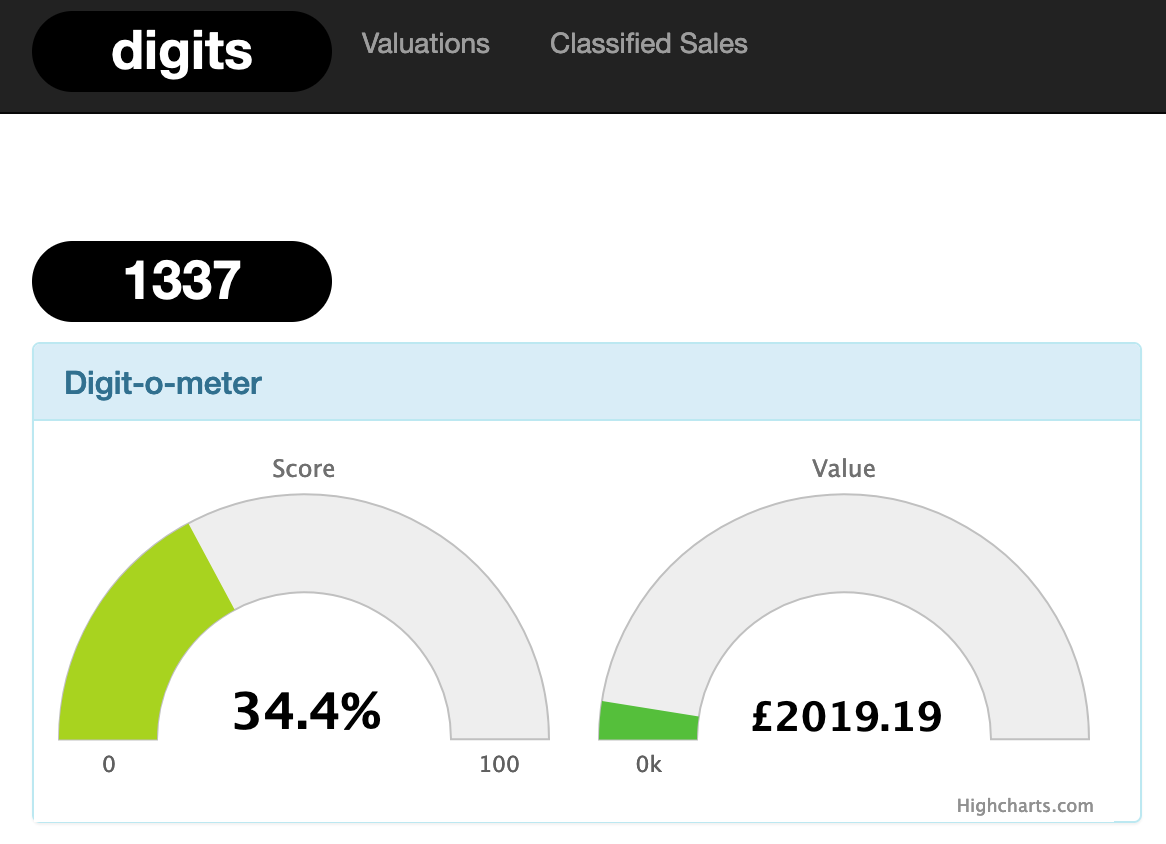
This was, indeed, a PHP website with a MySQL backend and probably not different in many ways from any of the PHP/MySQL websites I had been writing some 10+ years beforehand. Sure, now it had Bootstrap but beyond that it was the same. After all, it worked, and… what was the worst that could happen?
It was done quickly. Simply.
In fact, it was not as bad as it might have used to be. In the early days, SQL injection, URL hijacking and XSS and so on wasn’t a (known) thing. Parameterised queries in MySQL evolved from a need to provide more protection from unsafe user input, and, fortunately, by now, these were all things that I had an at least rudimentary awareness of and so the basic site was mostly safe from the usual tricks that attackers use to get in.
The site used a quasi-3-tier architecture (vaguely mimicking an MVC style approach) - it always had an API endpoint and possible app in the future in mind, so at the very least, the frontend was separated from the backend and even unvalidated client input was still validated on the server. Yay.
As time went on, though, things evolved, namely in two ways. (1) Family life changed which meant time to maintain the site became a lot more scarce. The app never happened. The valuations were updated less frequently. At the same time, (2), the growth of another project (centred around scraping data) came to life which initiated an additional purpose for the site - what better way to encourage traffic to the site about number plates than to list all the vehicles for sale in the area! Facepalm a little. (But, it seemed to make sense at the time.)
So with some scraper tech at hand, digits.gg started to list all the vehicles available for sale. Some new pages were cobbled together and a bit of tracking stuff was hacked in to place. It worked.
And it did this for a while. Scraping data daily, showing new vehicles. It showed them, and it allowed you to click out to the site advertising the vehicle. It recorded the clicks. It was fully automated but ultimately that functionally got fully moved over to the new project and became redundant on digits. The various system artefacts that existed - database tables, listing pages, click handlers, etc. - remained in place - but got commented out and were removed from public view. It was as if these things had never existed - but - and herein lies the problem - they very much did exist.
zzzzzz
It’s a ubiquitous phenomenon amongst techies that hobby projects get built with all the love and enthusiasm in the world at the time - but releasing them to the wild - except in unusual cases - has an uncanny habit of releasing the pressure valve and the thing is “done” - never to be touched again.
This is not entirely the case with digits - I still loved the project very much and still refreshed the valuations from time to time. But the reality is that the demands of work and life took over. A few quirks with the way it had been built meant it was a bit more awkward to update than it needed to be.
It’s had the odd emergency fix go in - there was no password reset functionality, there was no spam protection on the contact form and there was even a time when there was influx of sign-ups… accounts with a .ru extension that really made no sense. I frantically put in some account activation logic which seemed to deal with it. But otherwise, it’s remained as/is for the last 7 or so years: chugging away, virtually untouched, unmaintained, unloved.
The server it is hosted on hosts a number of other things but is mostly just “one of those” - i.e., it works whilst it works and really only gets looked at when it breaks.
I was checking on a broken thing somewhere else yesterday and happened upon a very curious discovery. Whilst all other sites on that server have some bandwidth and disk space limits in place… digits just so happened to be sitting on an old package that effectively allowed unlimited *everything*.
Big deal, you might think, but given that this is a low volume, non-changing website, the numbers surprised me:
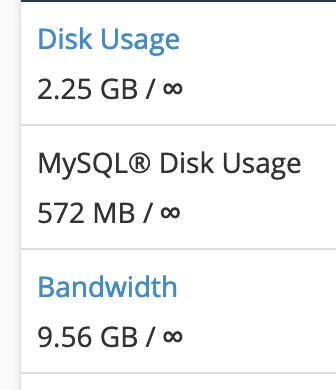
There is absolutely no reason on this green earth why any of those numbers should be anything like as high as they are. No reason at all.
This is not a popular site and it is not changing.
It is not content heavy.
It is not full of images or other media.
All of a sudden my “something smells fishy” siren is going off like crazy. Something, somewhere, was not right.
I won’t lie - this was pretty exciting.
It reminded me of a time when one of my other sites got hit by a bunch of trolls. It had a fairly open “comment board” that allowed non-authenticated commenting and one time a lot of very bored people thought it would be funny to shitpost some pretty disgusting abuse. As quick as I could block comments they would come back. It was real-time defence - eventually I implemented a block script that detected the trollers and automatically RickRolled them. I won. It was fun.
a-team music
Time to go to work.
The software the webhost runs allowed me to dig in to it a bit.
The disk space query was quickly answered - that 2.2gb comprised the 572mb of MySQL database and the rest, pretty much, taken up by tmp files from the multiple stats tracking packages.
In other words, the good news was that the server had not been compromised and was not hosting any sort of malicious payload or similar. I quickly verified this by firing up the trusty FTP client and having a good rummage around - and everything looked - so far as I could see - as it should. There were some large error_log files… but. Anyway.
So the stats were right and they were tracking a shedload of traffic - which presumably accounted for a lot of that 9.5gb of bandwidth. But the question was - where? What was this traffic?
quite big data
Time for a dig in the database. The 500mb database. I dredged the memory to recall what some of this was. There’s a table that contains all of the possible registration numbers - which is 101332 variants. (I had built-in capacity for all possible Guernsey car registrations, and some of the off-spec ones.) That table contained 101332 rows - OK.
Looking through some of the other tables, row counts look normal. Prices… a few hundred. Search History - ah, the log of what people on the site are searching for, this is higher - around 75,000 rows. But, the data looks normal. It’s what people have been searching for. 999 is there a fair bit. 007. OK.
Users - 500! Wow. I knew we had a few but didn’t think it was that many. User logins… a few more. Vehicles - the list of vehicles for sale that used to be displayed for sale on the site - 908. Same as the vehicle import table… 908.
Vehicle_Click: 3,367,600 rows.
What.
The.
Fuuuck
As much as I would love it - there is no way the site has generated 3 million clicks out to sites selling vehicles in Guernsey. I think we might have found something. Would this account for 500mb of data? I’m not sure, but it’s worth looking at.
The premise of this table was fairly simple. The site would show a summary listing of the vehicle for sale, plus a link out to the website that it was sourced from. If you clicked that link then as part of a redirect, it would log the ID of the item you clicked on, and for some (fortuitous, as we will see) reason the URL it was going to redirect to. Basic metrics of how popular the site was.
Scrolling through the early pages of this table all looked normal. Site IDs linking to legitimate looking URLs. Then - that’s weird. There’s a set of rows for an ID (corresponding to a vehicle) that link to.. http://www.google.com. What? Scroll a bit more, and back to normal. Must have been an anomaly. The datestamp on these entries is 2017-09-28.
All the rest of the early stuff looks normal. Page after page of normal looking clicks. Then… wait, an ID looks odd. It’s a normal looking ID but it has a bunch of random gibberish after it. Weird.
And then boom. 2017-11-02. An empty ID with a URL of /etc/passwd. And repeated attempts:
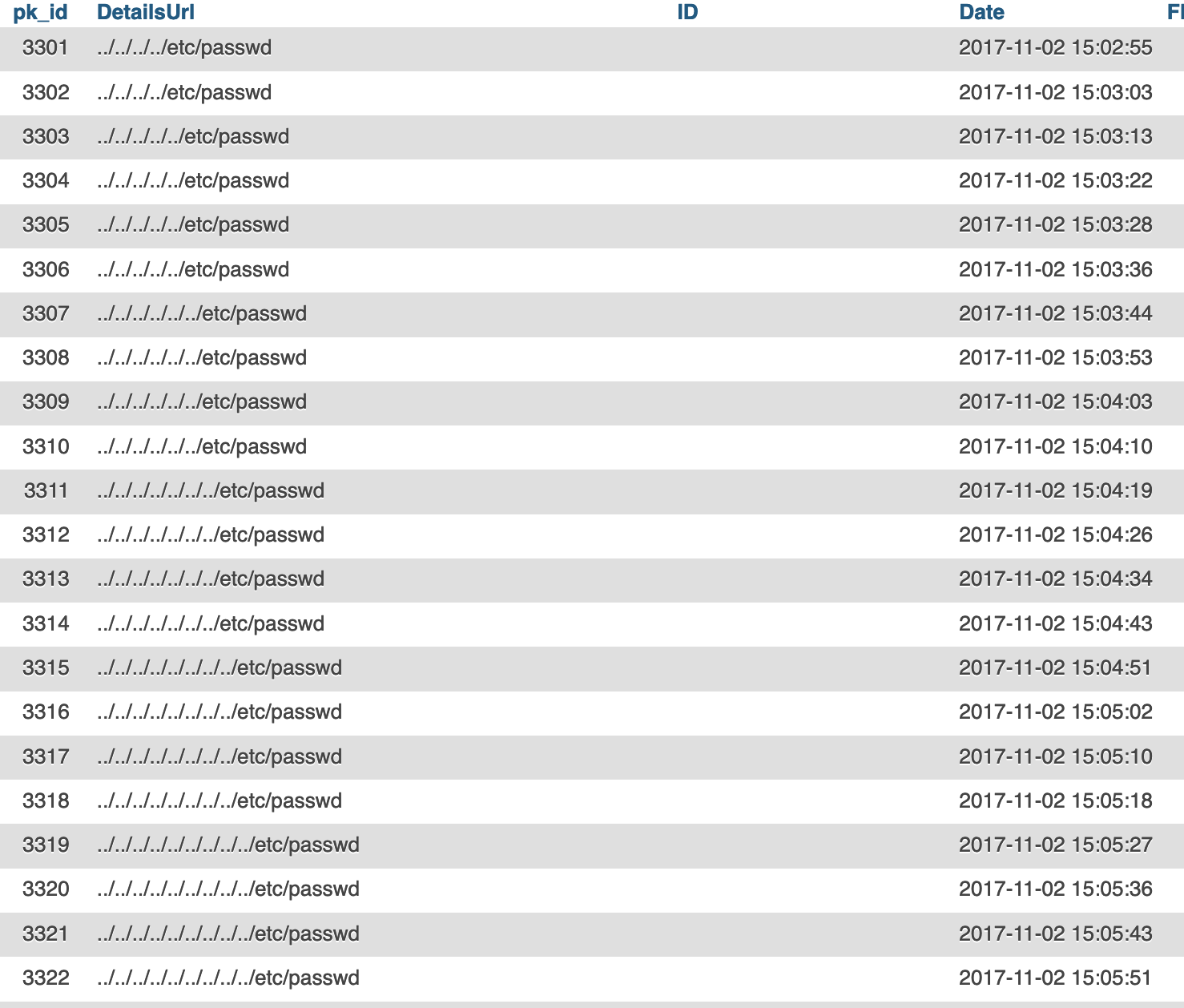
Then there’s the classic URL hijacking attempt:

That second entry is checking to see if I’ve properly encoded user input. Fortunately, I apparently had safeguarded against this, and this seemed to be a fairly short lived attack.
A few weeks later, though, someone else had a go:

This time attacking the ID field as opposed to the URL field. They were again looking for gaps in my SQL and trying to inject stuff that might give them a way in:

This lasted a little while, and then started to happen more regularly. (This could be the signature of an attack tool - I’m not sure - but that Benchmark stuff in the very specific casing crops up a lot, which smells of automated attack.)
Unfortunately, I didn’t record any sort of user agent so it’s impossible to tell how much of this stuff was done by bots.
We got a bit of respite for Christmas in 2017, but they were soon back in January 2018, this time with a different looking attack:
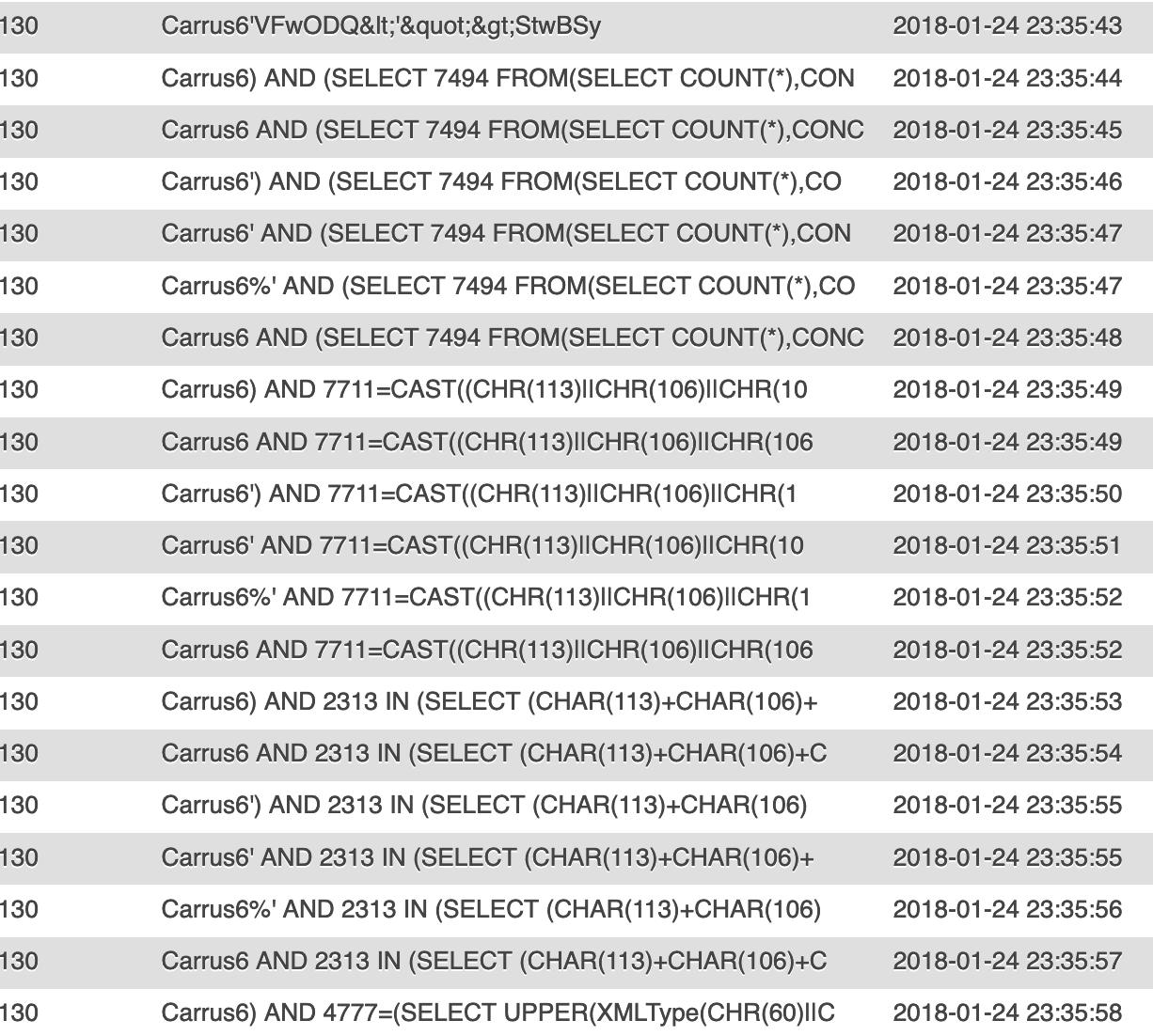
Quite what Carrus6 did to deserve this, I don’t know:
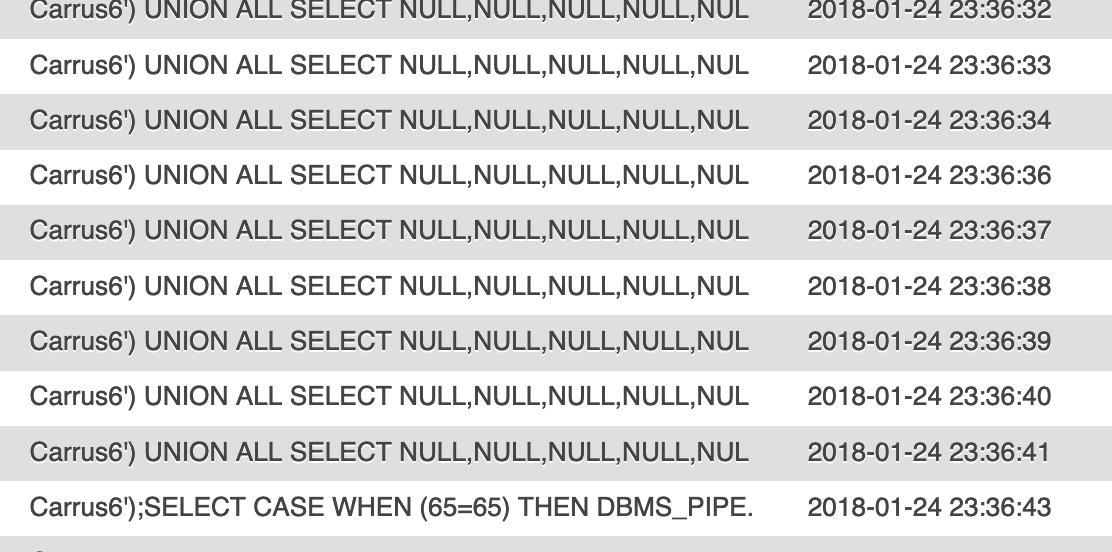
They also soon got bored.

There was also the usual sniffing around for other signature of, in this case, WordPress.
The sheer number of “clicks” this was generating is unbelievable - I assume the majority is search spiders / crawlers / bots, etc.
In February, the /etc/passwd attacks came back so I assume at this point the site had made it onto a list of sites to just periodically hit.
and then… huh
And so this continued. Through 2018, the same old stuff kept coming back. And I was completely oblivious to all of it- but the site was alive, and these attacks did not seem to be having any sort of impact. Month after month, the same stuff rolls in until September of 2019 when a really innocuous row in amongst everything else:

“Blogsdelagente” right there in the middle of otherwise legitimate clicks. This was the beginning. Thereafter things change:

Not much - just the odd few, here and there.
Then in November 2018, the balance tips, where the dodgy URLs start to exceed the real ones:

At this point, digits is no longer independently scraping the vehicle details. Instead, it’s taking a json feed from Seeker; this is getting updated daily, and the way it was implemented meant that the list effectively got refreshed - or perhaps more accurately, reset - every day.
Therefore we then go through a cycle of these spam URLs appearing, the vehicle list is reset, then nothing - until whatever’s indexing them comes around again and figures out what’s new and figures out the URLs to hit.
what is happening (has happened)
By 2019, though, digits had completely stopped showing any sort of vehicles, instead with a “you should go to Seeker” message.
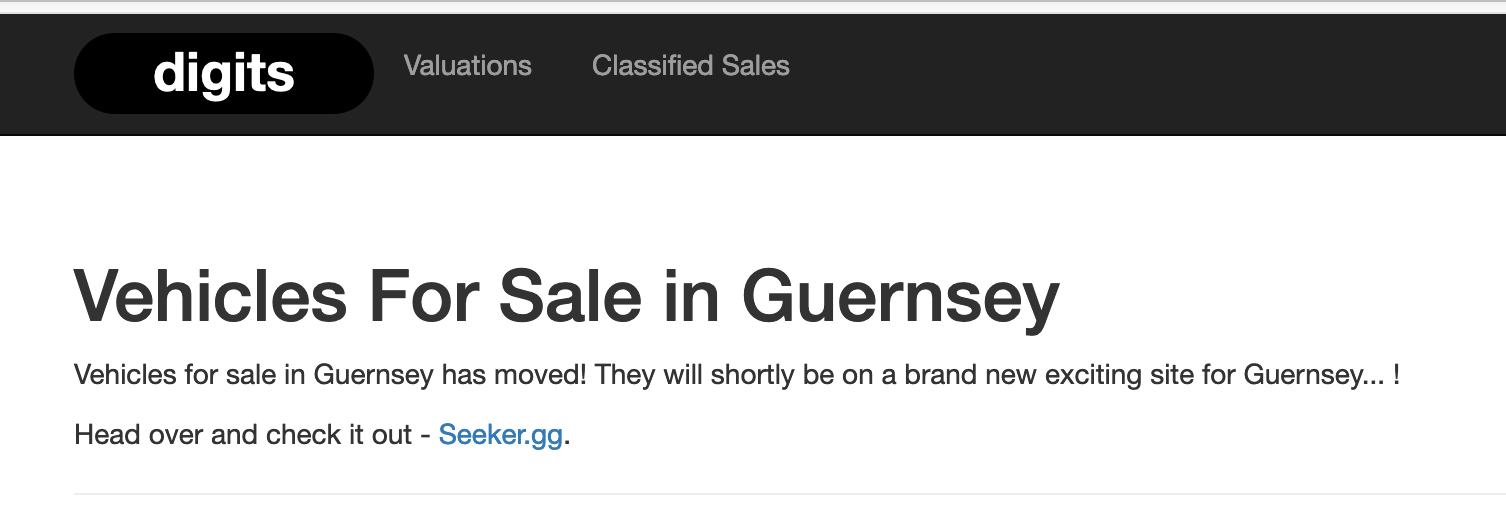
And yet the table click table was still filling up.
Time to see what is going on. The script files were still on the server and whilst hidden from public view, were still accessible to anyone who knew they existed. So basically virtually every search engine / spider out there. Facepalm. The initial premise was that you were on the “Vehicle” page, and by clicking the link to leave the site, you went via the “Vehicle Click” page which tracked the click and then redirected you.
Apparently this page did not get the same amount of attention as other pages.
The issue here should become apparent pretty quickly:
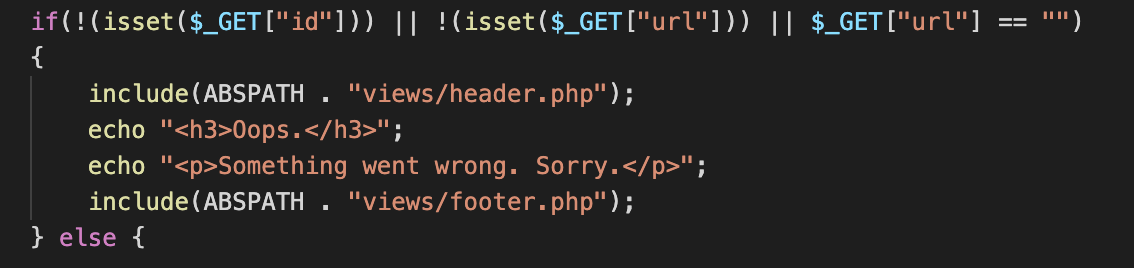
The page starts by checking that it has at least been given an ID and a URL and that the URL (but not the ID?) is not empty. If it failed that check, it dies. Not great, but OK.
But if you do give it those things, then it goes on, extracts what you passed in, checks if you were logged in (which was optional), and then when it’s done logging the hit, merrily redirects you to the URL:

BUT YES.
The issue is simple: it doesn’t do any sort of validation around the ID or the URL and so you can pass it literally whatever you like (other than empty string for the URL) and it will not only merrily log these details but then merrily redirect the browser to the URL specified.
More to the point, it doesn’t do any sort of validation that the referrer calling the script is actually allowed to call the script at all. Pretty schoolboy errors, looking at it now. (Hence my opening gambit: I’m not a web guy.)
The good news: the input is sanitised and can’t do any real harm to the server.
The bad news: I’ve basically created a massive sort of open spam proxy for literally anyone to use and abuse. They could use my normal looking domain (digits.gg) to redirect anyone to any location. For free and probably bypass all sorts of filters. I assume this is being used to pummel blogs and other comment forms around the world.
I feel a bit guilty.
boom
This was abused for most of 2019, and most of 2020. And, in the grand scheme of things, fairly lightly.
Until 2021. At some point, something somewhere realised this was a thing, and went absolutely beserk.
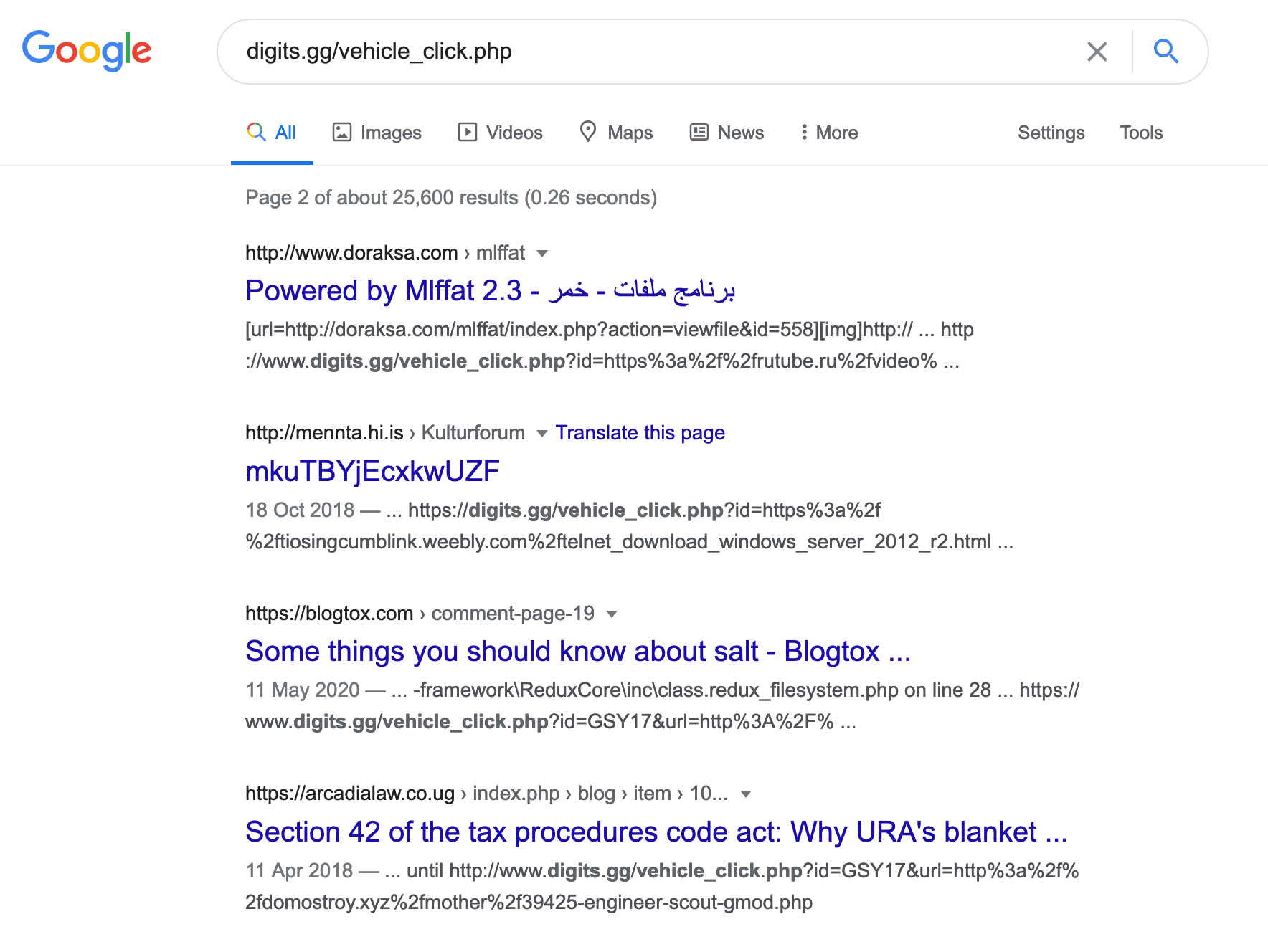
GSY17 got logged as the ID of choice:
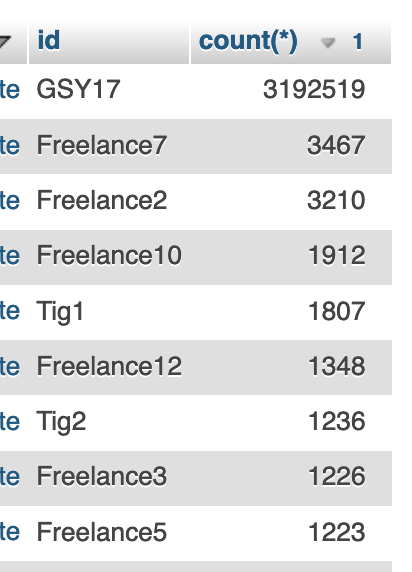
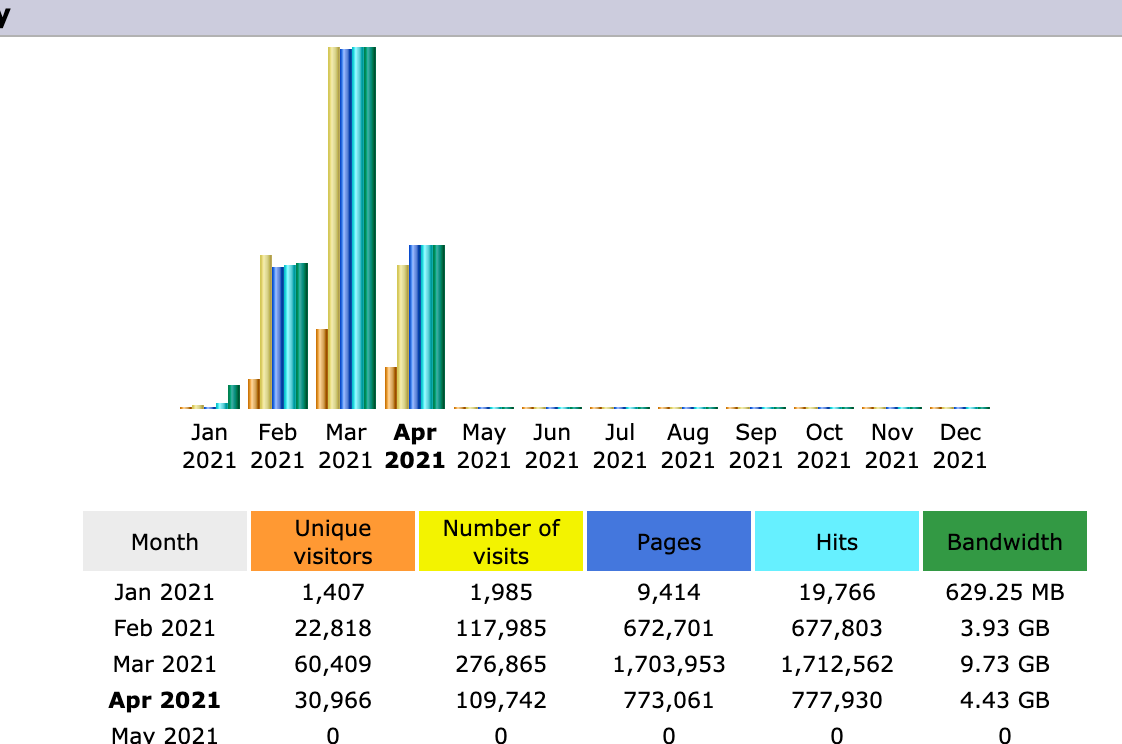
And in the space of a month, the hits had gone off the charts.:
I managed to download the 3m odd records in various separate files. And in the first 150mb file, you can see the weight:
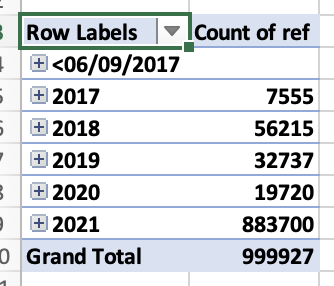
In Feb 2021, something picked it up:
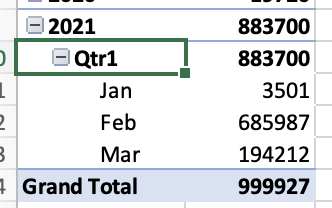
And it’s been going nuts ever since. (If I loaded in the other two files - both of which are 150mb+) you would see that in Mar-now is another 2 million records.
In the time it’s taken me to write this article, thousands of new rows have been added; all utter bollocks:

what to do
I probably shouldn’t start with this, but I’ve got to admit I’m highly impressed with how the website and the server is holding up to this literally constant barrage of abuse. I won’t credit my code for this. And, in the grand scheme of things this is probably but a drop in the ocean - it might explain why the people who run the hosting company haven’t been banging down my door asking what the hell is going on. Maybe they think I just run a really popular site.
By this point, I assume the spammers have graduated beyond the ‘Vehicles’ entry point and are now just hitting the ‘Click’ page directly. It’s a constant barrage of one a second or so.
If only I could write a legitimate site this popular!
On the one hand, I am currently accumulating a pretty handy list of spam URLs that your go-to spam blockers and Pi-Holes and the like would probably be pretty happy to get hold of?
And I’m also pretty curious about this traffic - it would be great, for instance, to see the referrer to see where it’s all coming from. The stats packages do tell some stories; these are the biggest sources:
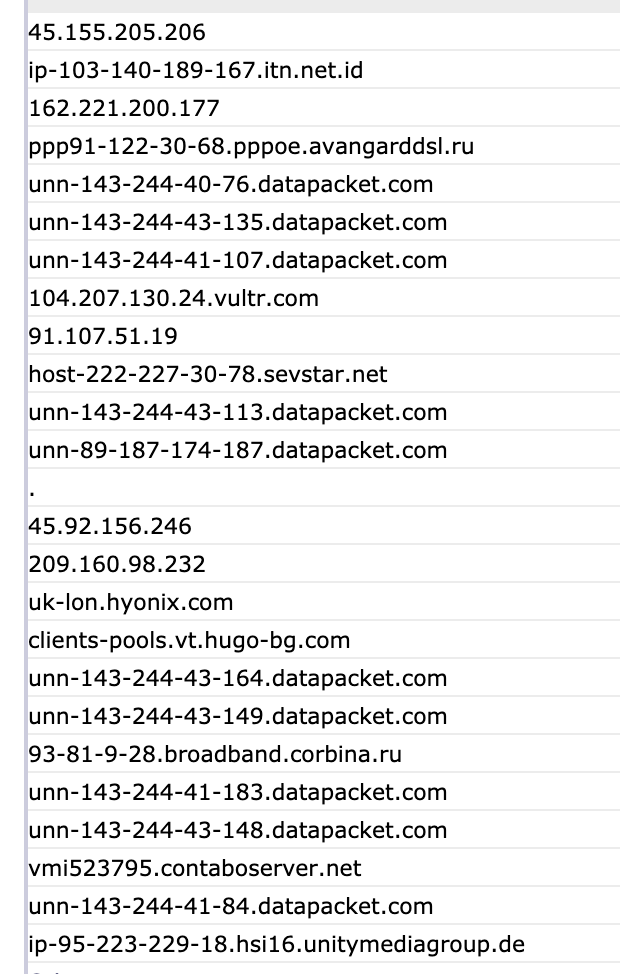
and
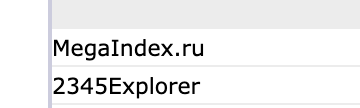
Showing as the big sources. This is a little suspicious:

But presumably the location is easy enough to spoof.
I feel like I need to shut it down it down though. I’m a little unsure the best way to do that - just deleting the scripts these things are hitting won’t stop the traffic; maybe returning a 404 or 500 or similar HTTP error would do it. I’m kind of concerned that a torrent of error statuses might actually take down the site. Although that would hardly be the end of the world.
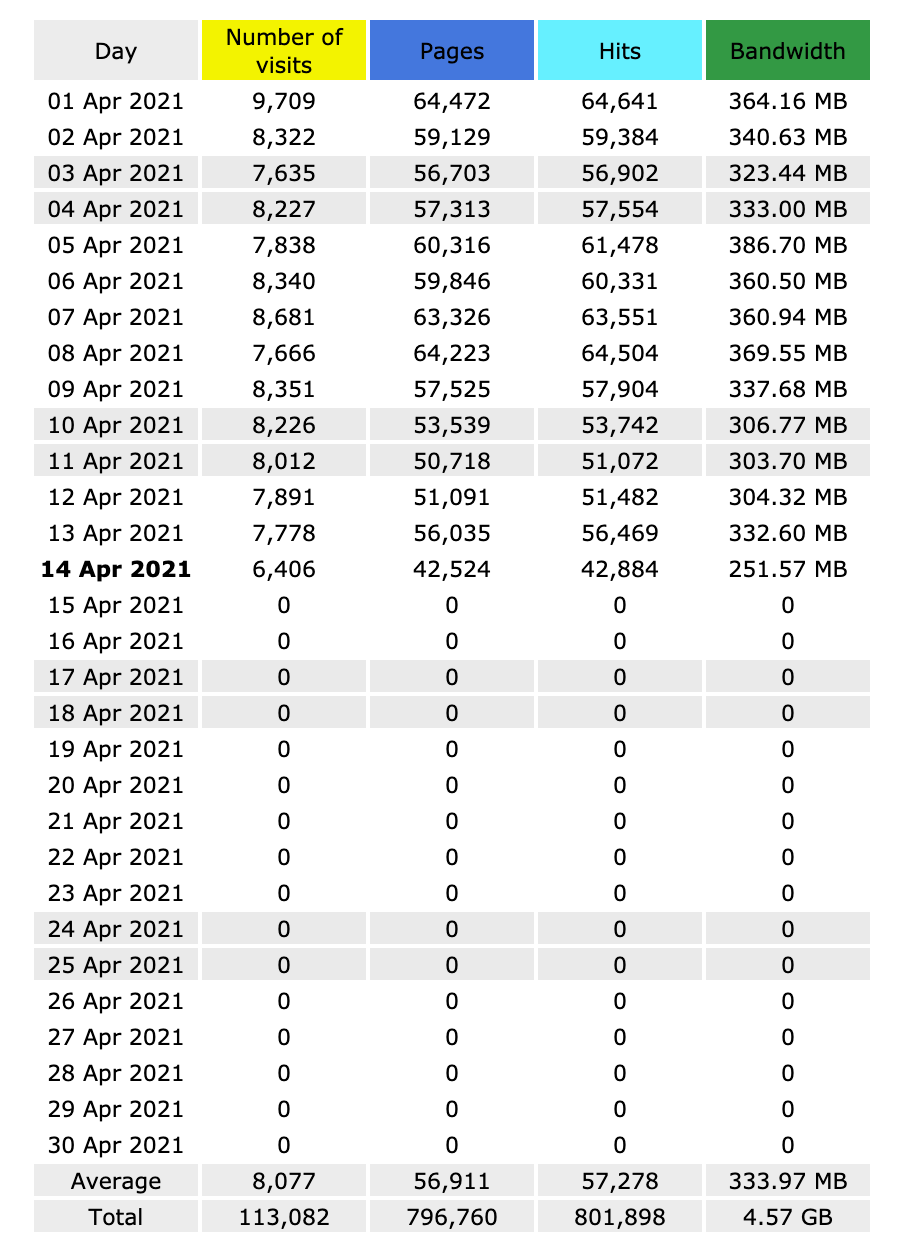
Let’s do that. At time of writing…

I expect to to see the 404 rise dramatically by tomorrow morning.
what did we learn?
Sanitising input is a good thing . I’m starting with that because I think we didn’t learn it here; rather, this has reinforced exactly how important it is. I take a probably misplaced pride that despite opening up this massive web nuisance, it was at least done in a suitably secure way that didn’t compromise the server.
Also, logging is good thing. Logging stuff is underrated in my view. Good software design should incorporate logging as an integral component. Without the log files, I would have had no idea what was going on nor indeed what had gone on.
I guess the main point here is: logs are only good if you look at them. This had been going on for moreorless 3 years and was undetected. I only found it now by fluke because I was looking for something else. That’s definitely a lesson.
Also: good tooling is vital. It’s easy to build the thing, make it work and release it to the wild, assuming it will work perfectly all the time. Proper tooling gives you the kit you need when things go wrong (and they will go wrong) to figure out what happened and how you fix it. My tooling was about 50/50.
Closing
There we have it. I’ll update again as hopefully the traffic goes away but I’ve definitely learnt a thing or two, and had a bit of fun along the way.
As a closing point, I’m going to reflect on my defence that “I’m not a web guy” - if there’s one thing we’ve seen seen over the last 12 months, it’s the convergence of web and conventional software. .NET 6 coming later in 2021 brings us closer to hybrid web/desktop environments and many of the new kid tricks that have been learnt for the web (think node.js / React / Angular… and lately Blazor) are increasingly encroaching and overtaking the norm for the full fat application.
Update 16/04/2021
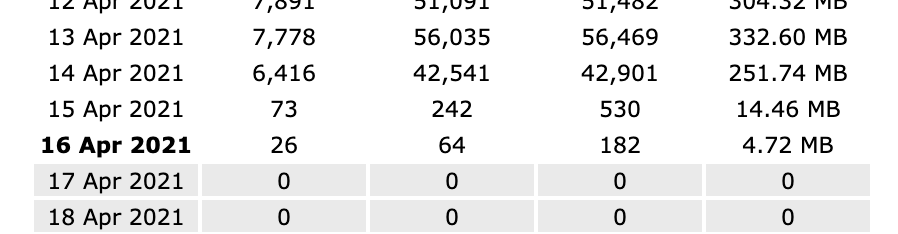
Looks like removing the page did the trick.

Hopefully they’ll soon get the message and bugger off.